Python Fundamentals
AdvancedSkill Level
15hrs
As one of the most popular programming languages out there, many people want to learn Python. But how do you go about getting started? In this guide, we explore everything you need to know to begin your learning journey, including a step-by-step guide and learning plan and some of the most useful resources to help you succeed.
Python is a high-level, interpreted programming language created by Guido van Rossum and first released in 1991. It is designed with an emphasis on code readability, and its syntax allows programmers to express concepts in fewer lines of code than would be possible in languages such as C++ or Java.
Python supports multiple programming paradigms, including procedural, object-oriented, and functional programming. In simpler terms, this means it’s flexible and allows you to write code in different ways, whether that's like giving the computer a to-do list (procedural), creating digital models of things or concepts (object-oriented), or treating your code like a math problem (functional).
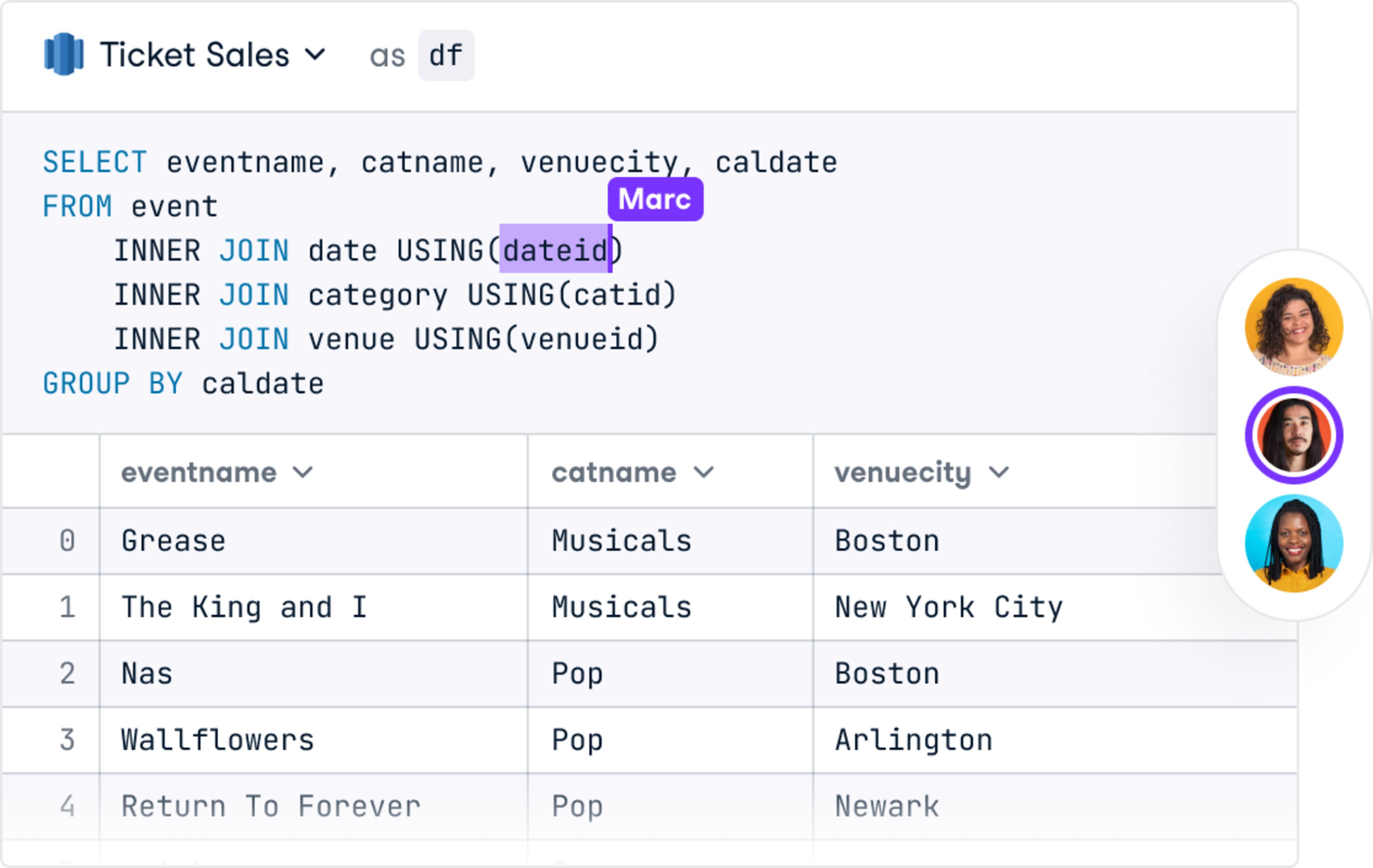
As of January 2024, Python remains the most popular programing language according to the TIOBE index. Over the years, Python has become one of the most popular programming languages due to its simplicity, versatility, and wide range of applications.
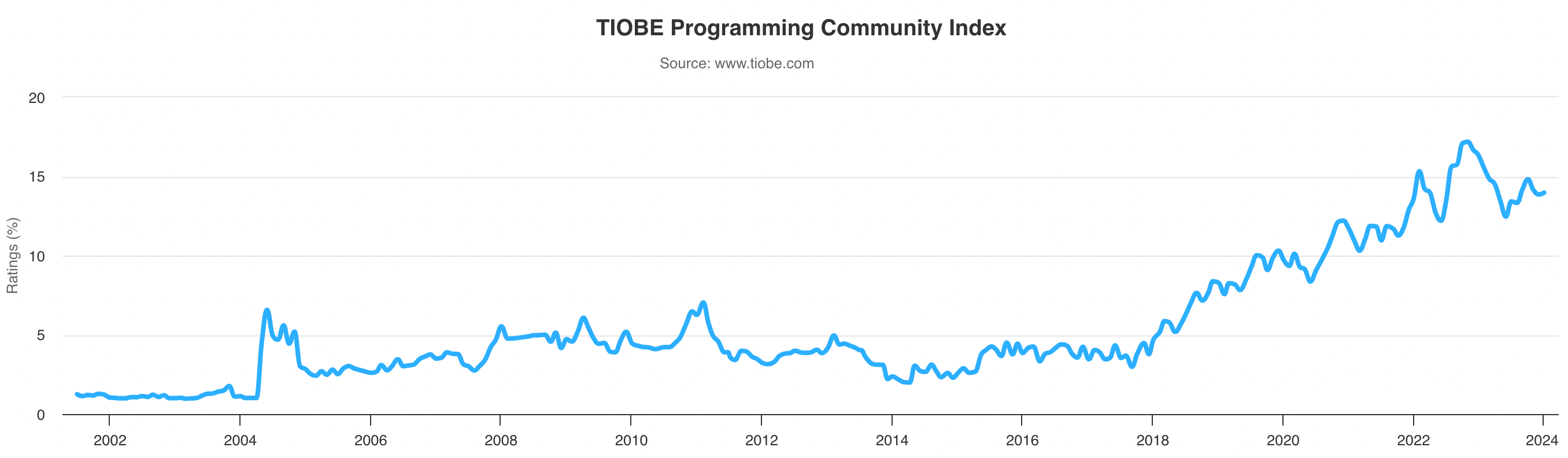
The popularity of Python
These reasons also mean it is a highly favored language for data science as it allows data scientists to focus more on data interpretation rather than language complexities.
Let’s explore these factors in more detail.
Let’s have a close look at some of the Python features that make it such a versatile and widely-used programming language:
Learning Python is beneficial for a variety of reasons. Besides its wide popularity, Python has applications in numerous industries, from tech to finance, healthcare, and beyond. Learning Python opens up many career opportunities and guarantees improved career outcomes. Here's how:
We’ve already mentioned the versatility of Python, but let’s look at a few specific examples of where you can use it:
With the rise of data science, machine learning, and artificial intelligence, there is a high demand for Python skills. According to a 2022 report from GitHub, Python usage increased 22.5% year on year, making it the third-most used language on the platform.
Companies across many industries are looking for professionals who can use Python to extract insights from data, build machine learning models, and automate tasks. Python certifications are also in demand.
Learning Python can significantly enhance your employability and open up a wide range of career opportunities. A quick search on the recruitment website Indeed for ‘Python’ finds over 60,000 jobs in the US requiring the skill.
While Python is one of the easier programming languages to learn, it still requires dedication and practice. The time it takes to learn Python can vary greatly depending on your prior experience with programming, the complexity of the concepts you're trying to grasp, and the amount of time you can dedicate to learning.
However, with a structured learning plan and consistent effort, you can often grasp the basics in a few weeks and become somewhat proficient in a few months.
Online resources can give you a firm basis for your skills and can range in length. As an example, our Python Programming skill track, covering the skills needed to code proficiently, takes around 24 study hours to complete, while our Data Analyst with Python career track takes around 36 study hours. Of course, the journey to becoming a true Pythonista is a long-term process, and much of your efforts will need to be self-study alongside more structured methods.
As a comparison of how long it takes to learn Python vs other languages:
|
Language |
Time to Learn |
|
Python |
1-3 months for basics, 4-12 months for advanced topics |
|
SQL |
1 to 2 months for basics, 1-3 months for advanced topics |
|
R |
1-3 months for basics, 4-12 months for advanced topics |
|
Julia |
1-3 months for basics, 4-12 months for advanced topics |
|
* The above comparisons are purely based on timelines needed to learn to become proficient with a programming language, not timelines needed to break into a career. Moreover, each person learns differently and goes at their own pace, we only aim to provide a framework with these timelines. |
|
A comparison table of how long it would take to learn different programming languages
Let’s take a look at how you can go about learning Python. This step-by-step guide assumes you’re at learning Python from scratch, meaning you’ll have to start with the very basics and work your way up.
Firstly, it’s important to figure out your motivations for wanting to learn Python. It’s a versatile language with all kinds of applications. So, understanding why you want to learn Python will help you develop a tailored learning plan.
Whether you're interested in automating tasks, analyzing data, or developing software, having a clear goal in mind will keep you motivated and focused on your learning journey. Some questions to ask yourself might include:
The answers to these questions will determine how to structure your learning path, which is especially important for the following steps.
Python is one of the easiest programming languages to pick up. What's really nice is that learning Python doesn't pigeonhole you into one domain; Python is so versatile it has applications in software development, data science, artificial intelligence, and almost any role that has programming involved with it!
Richie Cotton, Data Evangelist at DataCamp
Skip the installation process and experiment with data science code in your browser with DataLab, DataCamp's AI-powered notebook.
Full a full explanation of getting set up, check out our guide to how to install Python.
Start by writing a simple Python program, such as a classic "Hello, World!" script. This process will help you understand the syntax and structure of Python code. Our Python tutorial for beginners will take you through some of these basics.
Python offers several built-in data structures like lists, tuples, sets, and dictionaries. These data structures are used to store and manipulate data in your programs. We have a course dedicated to data structures and algorithms in Python, which covers a wide range of these aspects.
Control flow statements, like if-statements, for-loops, and while-loops, allow your program to make decisions and repeat actions. We have a tutorial on if statements, as well as ones on while-loops and for-loops.
Functions in Python are blocks of reusable code that perform a specific task. You can define your own functions and use built-in Python functions. We have a course on writing functions in Python which covers the best practices for writing maintainable, reusable, complex functions.
Once you’re familiar with the basics, you can start moving on to some more advanced topics. Again, these are essential for building your understanding of Python and will help you tackle an array of problems and situations you may encounter when using the programming language.
Python provides tools for handling errors and exceptions in your code. Understanding how to use try/except blocks and raise exceptions is crucial for writing robust Python programs. We’ve got a dedicated guide on exception and error handling in Python which can help you troubleshoot your code.
Python's power comes from its vast ecosystem of libraries. Learn how to import and use common libraries like NumPy for numerical computing, pandas for data manipulation, and matplotlib for data visualization. In a separate article, we cover the top Python libraries for data science, which can provide more context for these tools.
Python supports object-oriented programming (OOP), a paradigm that allows you to structure your code around objects and classes. Understanding OOP concepts like classes, objects, inheritance, and polymorphism can help you write more organized and efficient code.
To learn more about object-oriented programming in Python, check out our online course, which covers how to create classes and leverage techniques such as inheritance and polymorphism to reuse and optimize your code.
One of the most effective ways to learn Python is by actively using it. You want to minimize the amount of time you spend on learning syntax and work on projects as soon as possible. This learn-by-doing approach involves applying the concepts you've learned through your studies to real-world projects and exercises.
Thankfully, many DataCamp resources use this learn-by-doing method, but here are some other ways to practice your skills:
A range of Python projects on DataCamp Projects
As you complete projects, compile them into a portfolio. This portfolio should reflect your skills and interests and be tailored to the career or industry you're interested in. Try to make your projects original and showcase your problem-solving skills.
We’ve got a list of 60+ Python projects for all levels in a separate article, but here are a few suggested project ideas for different levels:
We’ve got a full guide on how to build a great data science portfolio, which covers a variety of different examples. And don’t forget; you can build your portfolio with DataCamp to show off your skills.
Never stop learning. Once you've mastered the basics, look for more challenging tasks and projects. Specialize in areas that are relevant to your career goals or personal interests. Whether it's data science, web development, or machine learning, there's always more to learn in the world of Python. Remember, the journey of learning Python is a marathon, not a sprint. Keep practicing, stay curious, and don't be afraid to make mistakes.
Below, we’ve created a potential learning plan outlining where to focus your time and efforts if you’re just starting out with Python. Remember, the timescales, subject areas, and progress all depend on a wide range of variables. We want to make this plan as hands-on and practical as possible, which is why we’ve recommended projects you can work on as you progress.
Master basic and intermediate programming concepts. Start doing basic projects in your specialized field. For example, if you're interested in data science, you might start by analyzing a dataset using pandas and visualizing the data with matplotlib.
Recommended resources & projects
Now that you have a solid foundation, you can start learning more advanced topics.
Recommended resources & projects
At this point, you should have a good understanding of Python and its applications in your field of interest. Now is the time to specialize.
Recommended resources & projects
If you’re eager to start your Python learning journey, it’s worth bearing these tips in mind; they’ll help you maximize your progress and keep focused.
Python is a versatile language with a wide range of applications, from web development and data analysis to machine learning and artificial intelligence. As you start your Python journey, it can be beneficial to choose a specific area to focus on. This could be based on your career goals, personal interests, or simply the area you find most exciting.
Choosing a focus can help guide your learning and make it more manageable. For example, if you're interested in data science, you might prioritize learning libraries like pandas and NumPy. If web development is your goal, you might focus on frameworks like Django or Flask.
Remember, choosing a focus doesn't mean you're limited to that area. Python's versatility means that skills you learn in one area can often be applied in others. As you grow more comfortable with Python, you can start exploring other areas and expanding your skill set.
Consistency is a key factor in successfully learning a new language, and Python is no exception. Aim to code every day, even if it's just for a few minutes. This regular practice will help reinforce what you've learned, making it easier to recall and apply.
Daily practice doesn't necessarily mean working on complex projects or learning new concepts each day. It could be as simple as reviewing what you've learned, refactoring some of your previous code, or solving coding challenges.
The best way to learn Python is by using it. Working on real projects gives you the opportunity to apply the concepts you've learned and gain hands-on experience. Start with simple projects that reinforce the basics, and gradually take on more complex ones as your skills improve. This could be anything from automating a simple task, building a small game, or even creating a data analysis project.
Learning Python, like any new skill, doesn't have to be a solitary journey. In fact, joining a community of learners can provide a wealth of benefits. It can offer support when you're facing challenges, provide motivation to keep going, and present opportunities to learn from others.
There are many Python communities you can join. These include local Python meetups, where you can connect with other Python enthusiasts in person and online forums where you can ask questions, share your knowledge, and learn from others' experiences.
Learning to code takes time, and Python is no exception. Don't rush through the material in an attempt to learn everything quickly. Take the time to understand each concept before moving on to the next. Remember, it's more important to fully understand a concept than to move through the material quickly.
Learning Python is an iterative process. As you gain more experience, revisit old projects or exercises and try to improve them or do them in a different way. This could mean optimizing your code, implementing a new feature, or even just making your code more readable. This process of iteration will help reinforce what you've learned and show you how much you've improved over time.
There are many ways that you can learn Python, and the best way for you will depend on how you like to learn and how flexible your learning schedule is. Here are some of the best ways you can start learning Python from scratch today:
Online courses are a great way to learn Python at your own pace. We offer over 150 Python courses for all levels, from beginners to advanced learners. These courses often include video lectures, quizzes, and hands-on projects, providing a well-rounded learning experience.
If you’re totally new to Python, you might want to start with our Introduction to Python course. For those looking to grasp all the essentials, our Python Fundamentals skill track covers everything you need to start programming.
Tutorials are a great way to learn Python, especially for beginners. They provide step-by-step instructions on how to perform specific tasks or understand certain concepts in Python.
We have a wide range of tutorials available related to Python and associated libraries. So whether you’re just getting started or hoping to improve your existing knowledge, you’re sure to find topics of interest.
If you’re looking for a fast way to brush up on specific Python principles, cheat sheets are a handy way to have a lot of knowledge in one resource. For example, our Python Cheat Sheet for Beginners covers many of the core concepts you’ll need to get started.
We also have cheat sheets for specific Python libraries, such as Seaborn and SciPy, which include example code snippets and tips to get the most out of the tools.

A selection of cheat sheets
Working on projects helps you utilize the skills you’ve learned already to tackle new challenges. As you work your way through, you’ll need to adapt your approach and research new ways of getting results, helping you to master new Python techniques.
You can find a whole range of data science projects to work on at DataCamp. These allow you to apply your coding skills to a wide range of datasets to solve real-world problems in your browser, and you can filter specifically by those that require Python.
Books are an excellent resource for learning Python, especially for those who prefer self-paced learning. Learn Python the Hard Way by Zed Shaw and Python Crash Course by Eric Matthes are two highly recommended books for beginners. These books provide in-depth explanations of Python concepts along with numerous exercises and projects to reinforce your learning.
As we’ve already seen, demand for professionals with Python skills is increasing, and there are many roles out there that require knowledge of the programming language. Here are some of the top careers that use Python you can choose from:
Data scientists are the detectives of the data world, responsible for unearthing and interpreting rich data sources, managing large amounts of data, and merging data points to identify trends.
They utilize their analytical, statistical, and programming skills to collect, analyze, and interpret large datasets. They then use this information to develop data-driven solutions to challenging business problems.
Part of these solutions is developing machine learning algorithms that generate new insights (e.g., identifying customer segments), automate business processes (e.g., credit score prediction), or provide customers with newfound value (e.g., recommender systems).
Key skills:
Essential tools:
Python developers are responsible for writing server-side web application logic. They develop back-end components, connect the application with the other web services, and support the front-end developers by integrating their work with the Python application. Python developers are also often involved in data analysis and machine learning, leveraging the rich ecosystem of Python libraries.
Key skills:
Essential tools:
Data analysts are responsible for interpreting data and turning it into information that can offer ways to improve a business. They gather information from various sources and interpret patterns and trends. Once data has been gathered and interpreted, Data analysts can then report back what they've found to the wider business to influence strategic decisions.
Key skills:
Essential tools:
Machine learning engineers are sophisticated programmers who develop machines and systems that can learn and apply knowledge. These professionals are responsible for creating programs and algorithms that enable machines to take action without being specifically directed to perform those tasks.
Key skills:
Essential tools:
|
Role |
Description |
Key Skills |
Tools |
|
Data Scientist |
Extracts insights from data to solve business problems and develop machine learning algorithms. |
Python, R, SQL, Machine Learning, AI concepts, statistical analysis, data visualization, communication |
Pandas, NumPy, Scikit-learn, Matplotlib, Tableau, Airflow, Spark, Git, Bash |
|
Python Developer |
Writes server-side web application logic, develops back-end components, and integrates front-end work with Python applications. |
Python programming, front-end technologies (HTML, CSS, JavaScript), Python web frameworks (Django, Flask), ORM libraries, database technologies |
PyCharm, Jupyter Notebook, Git, Django, Flask, Pandas, NumPy |
|
Data Analyst |
Interprets data to offer ways to improve a business, and reports findings to influence strategic decisions. |
Python, R, SQL, statistical analysis, data visualization, data collection and cleaning, communication |
Pandas, NumPy, Matplotlib, Tableau, MySQL, PostgreSQL, MS Excel |
|
Machine Learning Engineer |
Develops machines and systems that can learn and apply knowledge, and creates programs and algorithms for machine learning. |
Python, R, SQL, machine learning algorithms, deep learning frameworks |
Scikit-learn, TensorFlow, PyTorch, Pandas, NumPy, Matplotlib, Seaborn, TensorFlow, Keras, PyTorch |
A comparison table of jobs that use Python
A degree can be a great asset when starting a career that uses Python, but it's not the only pathway. While a formal education in computer science or a related field can be beneficial, more and more professionals are entering the field through non-traditional routes. With dedication, consistent learning, and a proactive approach, you can land your dream job that uses Python.
Here's how to find a job that uses Python without a degree:
Stay updated with the latest developments in Python. Follow influential Python professionals on Twitter, read Python-related blogs, and listen to Python-related podcasts. Some of the Python thought leaders to follow include Guido van Rossum (the creator of Python), Raymond Hettinger, and others. You'll gain insights into trending topics, emerging technologies, and the future direction of Python.
You should also check out industry events, whether it’s webinars at DataCamp, Python conferences, or networking events.
Building a strong portfolio that demonstrates your skills and completed projects is one way to differentiate yourself from other candidates. Importantly, showcasing projects where you've applied Python to address real-world challenges can leave a lasting impression on hiring managers.
As Nick Singh, author of Ace the Data Science Interview, said on the DataFramed Careers Series podcast,
The key to standing out is to show your project made an impact and show that other people cared. Why are we in data? We're trying to find insights that actually impact a business, or we're trying to find insights that will actually shape society or create something novel. We're trying to improve profitability or improve people's lives using and analyzing data, so if you don’t somehow quantify the impact, then you are lacking impact.
Nick Singh, Author of Ace the Data Science Interview
60% to 70% of applications get shifted out of consideration before humans actually look at the application.
Jen Bricker, Former Head of Career Services at DataCamp
Amberle McKee
Adel Nehme
Amberle McKee
Adel Nehme
Bex Tuychiev
Adel Nehme



